【Python】非同期処理で支える AI の社会実装 | asyncio 入門
AI を活用したサービスでは、AI の呼び出し自体に数秒かかることが珍しくありません。それに加えて、AI を呼び出す前に、複数のデータソースから情報を集める必要がある場合がほとんどです。
例えば、社内の AI アシスタントがユーザーの技術的な質問に答えるためには、
- 社内ドキュメントを全文検索(3秒)
- ベクトルデータベースで類似検索(3秒)
- 社内チャットの過去ログを検索(3秒)
- 集めた情報を LLM に渡して回答生成(4秒)
というように、時間のかかる処理を複数実行していかなくてはなりません。
これをナイーブな実装で、そのまま1つずつ順に実行すると、合計13秒もかかってしまいます。どうにかならんでしょうか。
よく考えてみると、最初の3つの検索は互いに依存していないので、並行して実行できるはずです。ここに、非同期処理によるパフォーマンス改善の余地があります。
本記事では、Python の asyncio で非同期処理に入門し、AI を活用したサービスにおけるパフォーマンス改善の例を簡単にご紹介します。
目次
- そもそも非同期処理とは?
- 同期処理の世界
- 非同期処理の考え方
asyncioの基本概念- コルーチン
- await (待機)
- イベントループ
asyncioのコードサンプル- 同期処理の問題
asyncioによる非同期処理化- コードの解説
asyncioでよくある間違いawaitを付け忘れる- 通常の関数内で
awaitを使う
- まとめ
そもそも非同期処理とは?
同期処理の世界
通常のPythonコードは同期的に実行されます。つまり、1行ずつ順番に実行され、前の処理が完全に終わるまで次の処理は始まりません。
例えば、1秒かかる処理A、2秒かかる処理B、3秒かかる処理Cがあるとして、これらを同期的に実行すると…
# 同期処理のイメージ
処理A # まずは1秒待つ
処理B # 続いて2秒待つ
処理C # さらに3秒待つ
# 合計6秒このように、 1 + 2 + 3 で合計6秒かかります。
非同期処理の考え方
非同期処理とは、ある処理の完了を待たずに次の処理を開始するような仕組みのことをいいます。
従来の同期処理では、データベースへのアクセスやAPIの呼び出しなど、時間のかかるI/O処理の間、プログラムは何もせずに待機しています。この待ち時間は「ブロッキング」と呼ばれ、CPUは有効活用されていません。
非同期処理では、I/O処理の完了を待っている間に、他の処理を進めることができます。例えば、3つのAPIを呼び出す必要がある場合、1つ目のAPIの応答を待っている間に、2つ目、3つ目のAPIへのリクエストを送信できます。これにより、全体の処理時間を大幅に短縮できます。
同期処理と非同期処理の違いは、パン屋さんで例えてみるとわかりやすいです。
同期処理の店員は、クロワッサンをオーブンに入れて、焼きあがるまでの15分間ずっとオーブンの前で立ち尽くします。雇用主は解雇を検討するかもしれません。
一方、非同期処理の店員は、クロワッサンをオーブンに入れたら、すぐにメロンパンとカレーパンの準備を始め、タイマーがなったらクロワッサンを取り出す動きをします。
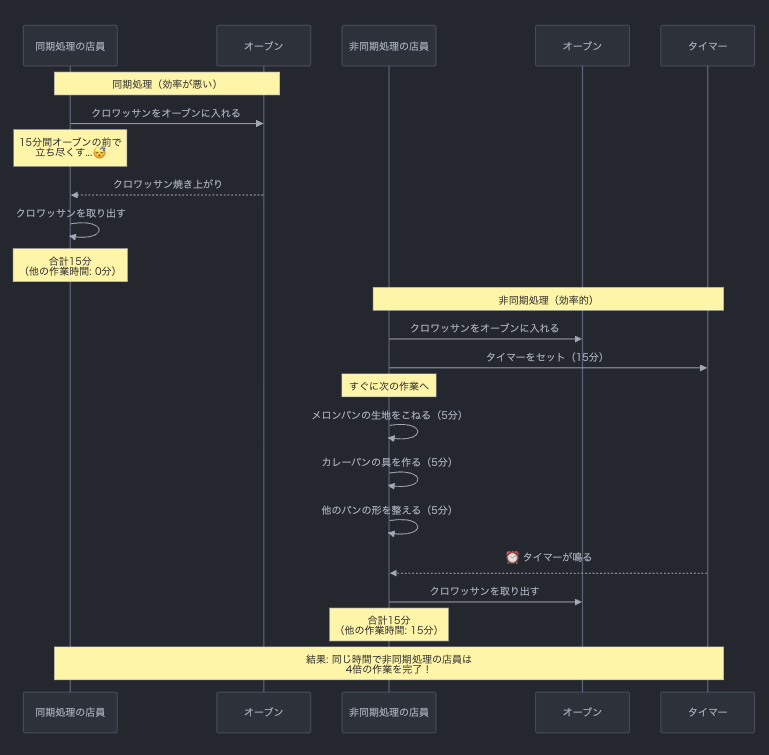
このように非同期処理では、ある処理が「待ち」に入ったら、その間に他の処理を進めることができます。
# 非同期処理のイメージ
処理A開始 # 完了を待たず次へ
処理B開始 # 完了を待たず次へ
処理C開始 # 完了を待たず次へ
# 3つの処理が並行で実行されている
A, B, C 全ての完了を待つ # 最も重い処理Cと同じくらいの時間(3秒)で全て完了asyncio の基本概念
それでは、Python で非同期処理を実装するために、asyncio を学んでいきましょう。
まずは基本的な概念を整理します。
1. コルーチン
async defで定義された関数はコルーチン関数と呼ばれます。通常の関数と違い、実行を一時停止・再開できる特殊な関数です。
# 通常の関数
def normal_function():
return "結果"
# コルーチン関数
async def coroutine_function():
return "結果"重要な点は、コルーチン関数を呼び出すと、すぐに実行されるのではなくコルーチンオブジェクトが返されることです。
# 通常の関数:呼び出すと即座に実行され、結果が返る
result = normal_function()# "結果"# コルーチン関数:呼び出すとコルーチンオブジェクトが返る(まだ実行されない)
coro = coroutine_function()# <coroutine object coroutine_function at 0x...># コルーチンオブジェクトを実行するにはawaitが必要
result = await coro# "結果"2. await(待機)
awaitは2つの役割を持ちます:
- コルーチンオブジェクトを実際に実行する
- I/O処理の間、他の処理に実行を譲る
async def fetch_data():
# awaitでコルーチンオブジェクトを実行し、# I/O待機中は他の処理に実行を譲る
result = await some_io_operation()
return resultawaitは「ここで一時停止して、他の処理に順番を譲ってもいいよ」という印です。I/O処理(ネットワーク通信、ファイル読み書きなど)の前に付けます。
3. イベントループ
asyncio の心臓部です。どのコルーチンを実行するか管理し、I/O待機中のコルーチンと実行可能なコルーチンを切り替えます。通常はasyncio.run()が自動的にイベントループを作成・管理します。
同期処理の問題
まず、同期的な(ナイーブな)コードを見てみましょう。
冒頭での例を簡単なコードで表しました。AIアシスタントの質問に13秒かかるケースです。
import time
def search_documents(query):
print("社内ドキュメントを検索中...")
time.sleep(3.0) # 数TB規模のドキュメントから全文検索
return "関連ドキュメント: API設計ガイドライン、エラーハンドリング規約"
def search_vectors(query):
print("ベクトルDBで類似検索中...")
time.sleep(3.0) # 数百万件のベクトルから意味的に類似した文書を検索
return "類似コンテンツ: 過去のトラブルシューティング事例"
def search_chat_logs(query):
print("社内チャットログを検索中...")
time.sleep(3.0) # 大量のメッセージ履歴から関連する議論を抽出
return "チャット履歴: 開発チームでの解決策の議論"
def generate_answer(query, context):
print("LLMで回答を生成中...")
time.sleep(4.0) # 詳細で正確な回答の生成
return f"回答: {query}について、{context}を基に説明します"
# ユーザーの質問を処理
start = time.time()
query = "APIのレート制限エラーの解決方法を教えて"
# 順番に情報を収集
doc = search_documents(query)
similar = search_vectors(query)
chat = search_chat_logs(query)
# 収集した情報を結合
context = f"{doc}, {similar}, {chat}"
# LLMで回答生成
answer = generate_answer(query, context)
print(f"\\n{answer}")
print(f"処理時間: {time.time() - start:.1f}秒")
# 出力: 処理時間: 13.0秒asyncio による非同期処理化
同じ処理を asyncio を用いて、非同期処理に書き直してみましょう。
import asyncio
import time
# async defでコルーチンを定義
async def search_documents_async(query):
print("社内ドキュメントを検索中...")
# awaitで非同期的に待機(この間、他の処理が実行可能)
await asyncio.sleep(3.0)
return "関連ドキュメント: API設計ガイドライン、エラーハンドリング規約"
async def search_vectors_async(query):
print("ベクトルDBで類似検索中...")
await asyncio.sleep(3.0)
return "類似コンテンツ: 過去のトラブルシューティング事例"
async def search_chat_logs_async(query):
print("社内チャットログを検索中...")
await asyncio.sleep(3.0)
return "チャット履歴: 開発チームでの解決策の議論"
async def generate_answer_async(query, context):
print("LLMで回答を生成中...")
await asyncio.sleep(4.0)
return f"回答: {query}について、{context}を基に説明します"
async def process_query(query):
start = time.time()
# asyncio.gather()で複数のコルーチンを並行して実行
# 3つの検索が並行に実行される
doc, similar, chat = await asyncio.gather(
search_documents_async(query),
search_vectors_async(query),
search_chat_logs_async(query)
)
# 収集した情報を結合
context = f"{doc}, {similar}, {chat}"
# LLMで回答生成(これは前の処理が終わってから実行)
answer = await generate_answer_async(query, context)
print(f"\\n{answer}")
print(f"処理時間: {time.time() - start:.1f}秒")
return answer
# asyncio.run()でイベントループを起動し、コルーチンを実行
query = "APIのレート制限エラーの解決方法を教えて"
asyncio.run(process_query(query))
# 出力: 処理時間: 7.0秒処理時間が13秒から7秒に短縮されました!ほぼ半分の時間で処理が完了します。
コードサンプルの解説
ざっくり、下図のような挙動をしています。
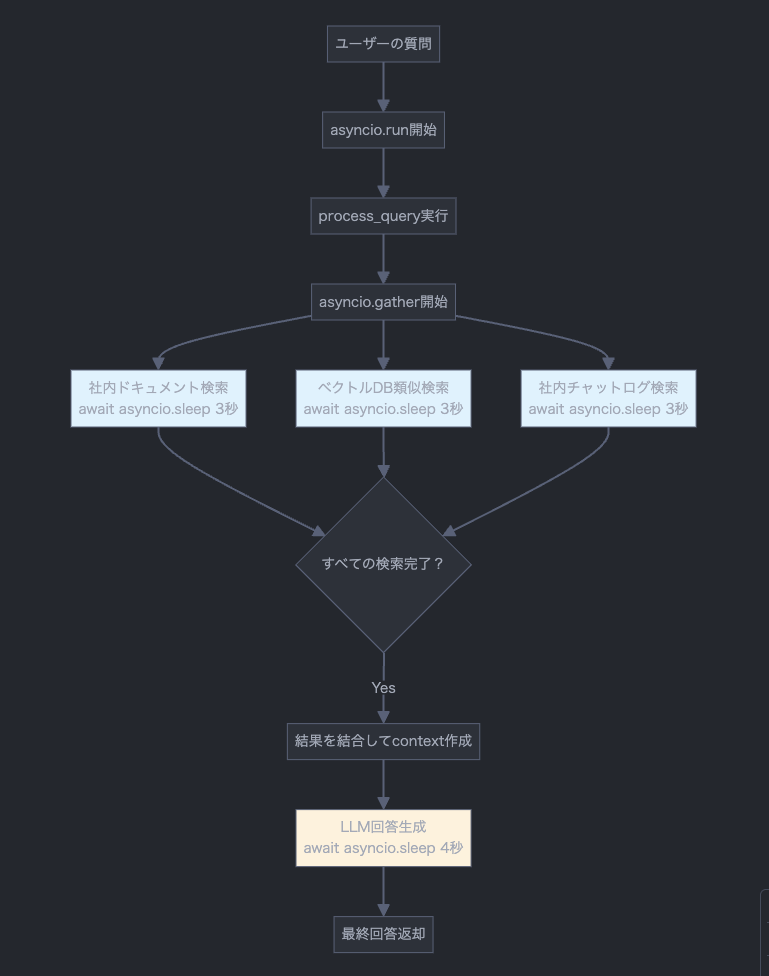
重要な部分のコードをそれぞれ確認していきましょう。
1. async def - コルーチンの定義
async def search_documents_async(query):
# この関数はコルーチン
await asyncio.sleep(3.0)
return "結果"async defで定義された関数は、呼び出しただけでは実行されません。コルーチンオブジェクトを返します。
2. await - 非同期的な待機
await asyncio.sleep(3.0) # 3秒間、他の処理に実行を譲るawaitがあると、その処理が完了するまで一時停止し、イベントループは他のコルーチンを実行できます。
3. asyncio.gather() - 複数のコルーチンを並行して実行
doc, similar, chat = await asyncio.gather(
search_documents_async(query),
search_vectors_async(query),
search_chat_logs_async(query)
)asyncio.gather()は複数のコルーチンを受け取り、それらを並行に実行します。全てが完了すると、結果をタプルで返します。
4. asyncio.run() - エントリーポイント
asyncio.run(process_query(query))これがプログラムのエントリーポイントです。イベントループを作成し、指定されたコルーチンを実行し、完了したらイベントループを閉じます。
実行の流れ
asyncio.run()がイベントループを起動process_query()が実行開始asyncio.gather()で3つの検索が並行してスタート- 各検索が
await asyncio.sleep(3.0)に到達すると、イベントループは他の検索に処理を切り替える - 約3秒後、全ての検索が完了
- LLMの処理を実行(4秒)
- 結果を返して終了
asyncio でよくある間違い
await を付け忘れる
# 間違い
async def main():
result = search_documents_async("test") # awaitがない!
print(result) # <coroutine object ...> が表示される
# 正しい
async def main():
result = await search_documents_async("test")
print(result) # "関連ドキュメント: API設計ガイドライン..." が表示される
通常の関数内で await を使う
# エラー:通常の関数内でawaitは使えない
def normal_function():
result = await some_async_function() # SyntaxError!
# 正しい:async関数内でのみawaitが使える
async def async_function():
result = await some_async_function() # OK
まとめ
asyncio を使うことで、1つのリクエスト内で発生する複数のI/O処理を効率化できます。
覚えるべきことは4つだけ!
async defでコルーチン(非同期関数)を定義awaitでI/O処理を非同期的に待機asyncio.gather()で複数のコルーチンを並行して実行asyncio.run()でイベントループを起動
特にRAGシステムのように、複数のデータソースから情報を集めて LLM に渡すようなアプリケーションでは、asyncio による非同期処理化が必須の技術となります。実際、LLM を活用したサービスの API コードサンプルを確認すると asyncioを併用しているケースが少なからず見受けられます。
\ 宣伝 /
株式会社Biz Freak は、AI の社会実装を積極的に推し進めながら、新規事業に特化した伴走型アジャイル開発サービス『バクソク』を展開しています。

.png&w=3840&q=75)
