【2025年6月版】生成AIモデル徹底比較:ビジネス向けLLM選定ガイド
2年以上前に登場したChatGPTは、ビジネスにおけるAI活用の可能性を大きく広げました。そして2025年6月現在、OpenAI、Google、Anthropicに加え、xAIやDeepSeekといった新たなプレイヤーも登場し、LLM(大規模言語モデル)市場はさらなる進化と競争の激化を見せています。各社から多様なモデルが提供される中、自社に最適なLLMを選定することは、ますます重要かつ複雑になっています。
本記事では、2025年上半期の最新動向を踏まえつつ、前回同様「クオリティ」「コスト」「スピード」という3つの重要指標の観点から各サービスの特徴を比較し、LLM選定のポイントを解説します。
目次
- 2025年上半期LLM最新動向
- LLMを比較する3つの重要指標
- クオリティ:用途に応じた「使える」品質とは
- コスト:ROIを最大化する選択を
- スピード:業務効率に直結する応答性能
- 主要サービスの特徴と選び方
- OpenAI:GPTシリーズ、oシリーズ
- Google:Geminiシリーズ
- Anthropic:Claudeシリーズ
- xAI:Grokシリーズ
- DeepSeek:DeepSeek R1シリーズ
- LLM選定の基本フロー
- まとめ
2025年上半期LLM最新動向
2025年上半期のLLM市場は、企業によるモデル選定に影響を与える大きな変化を見せました。
- 新モデル登場と性能向上、選択肢の多様化:
- OpenAIから「oシリーズ」「GPT-4.1シリーズ」、Googleから「Gemini 2.5 Pro/Flash」、Anthropicから「Claude Sonnet/Opus 4 」など、主要プレイヤーの新モデルが続々登場。
- xAI「Grokシリーズ」やDeepSeek「DeepSeek R1シリーズ」といった高性能モデルも新規参入し、選択肢が大幅に増加しました。
- 推論能力と専門性の強化:
- 複雑な指示理解、専門知識活用、論理的推論能力が大幅に向上。特にOpenAI「oシリーズ」、Anthropic「Thinking」モデル群、DeepSeek R1シリーズがこの傾向を牽引しています。
- コンテキストウィンドウの飛躍的拡大:
- Google「Gemini 2.5 Pro」は最大100万トークンを実現するなど、一度に扱える情報量が飛躍的に増大。長文理解や複雑な対話維持が容易になりました。
- コスト効率と応答速度の追求:
- 最高性能モデルに加え、特定タスクに最適化された小型・高速・低コストなモデル(例:GPT-4.1-mini, Gemini 2.5 Flash)も拡充。用途に応じた使い分けの重要性が増しています。
- マルチモーダル機能の標準化:
- テキストに加え、画像、音声、動画などを統合処理するマルチモーダル機能が、多くの主要モデルで標準搭載されつつあります。
- 評価指標の進化:
- 従来のMMLU(文章理解・生成能力)に加え、GPQA(推論能力)やHumanEval(コーディング能力)など、より実践的な能力を測る新指標の重要性が高まっています。
これらの動向は、企業がLLMを選定する上で、性能、コスト、特定用途への適合性など、より多角的な視点と戦略的な判断が不可欠であることを示しています。
LLMを比較する3つの重要指標
クオリティ:用途に応じた「使える」品質とは
LLMの品質は、使用目的によって求められる水準が大きく異なります。例えば、カスタマーサポート用のチャットボットと、技術文書作成支援では、必要とされる能力が全く違います。ここでは、主要な3つの評価指標から見ていきましょう。これらの指標はあくまで参考であり、実際の業務データを用いた評価が不可欠です。
文章理解・生成能力(MMLU)、推論能力(GPQA)
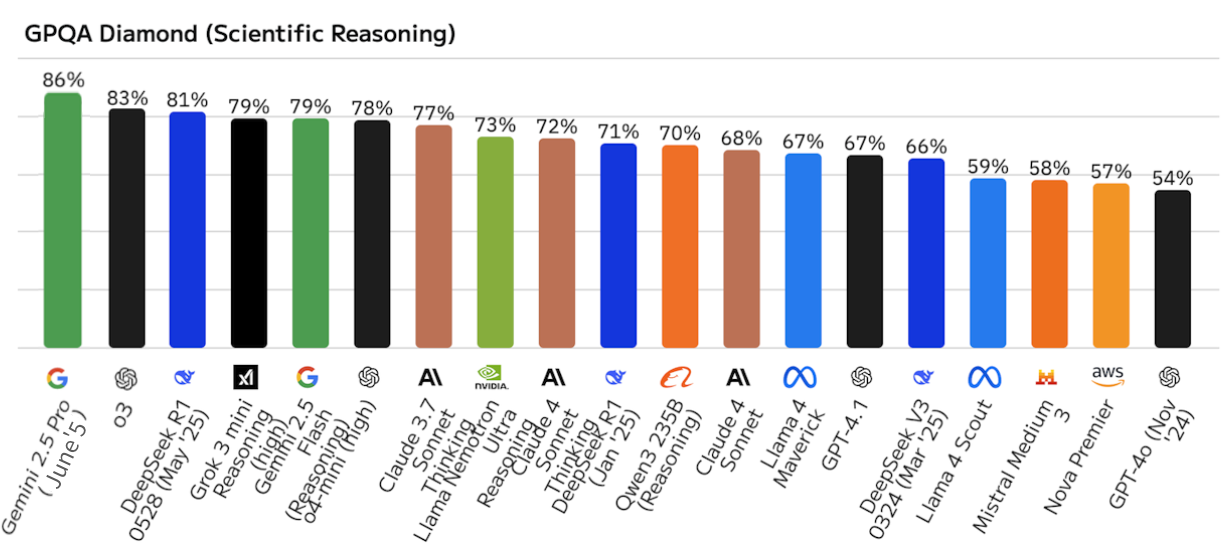
MMLU (Massive Multitask Language Understanding) は、モデルの幅広い知識と文章理解力、推論能力を測定する代表的な指標の一つです。また、より高度な推論能力を測るGPQA (Graduate-Level Google-Proof Q&A) なども注目されています。これらの数値が高いモデルは、以下のようなタスクに強みを発揮します。
実務での活用例
- 長文レポートの要約・作成
- 技術文書の執筆支援
- 市場調査レポートの分析
- 複雑な問い合わせへの対応
数学的推論能力(MATH-500)
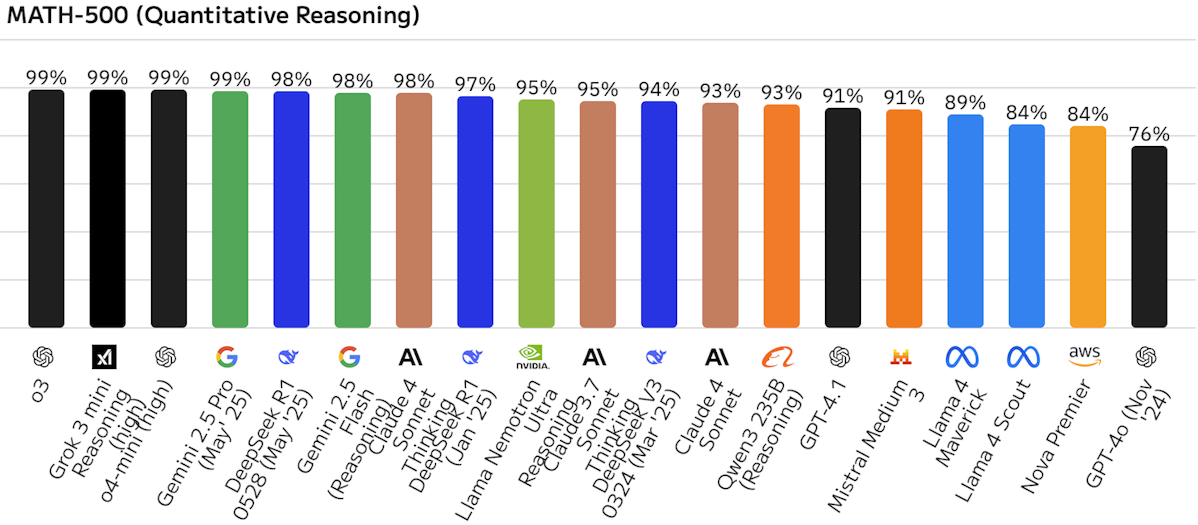
数値データの処理や論理的な思考を必要とするタスクの正確性を示します。
実務での活用例
- 財務分析・予測
- データ分析レポートの作成
- 統計処理を伴う調査分析
- 複雑なロジックを含む業務プロセスの自動化
コーディング能力 (HumanEval)
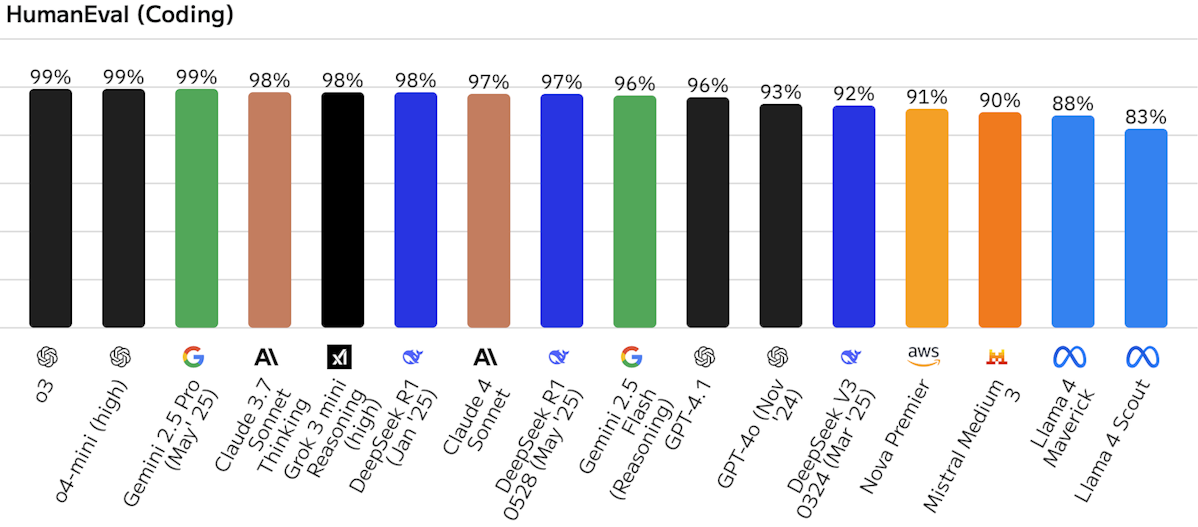
プログラミング関連タスクの正確性と効率性を評価します。HumanEvalに加え、より実践的なリポジトリレベルのコーディング能力を測るSWE-Benchなどが注目されています。
実務での活用例
- アプリケーション開発支援、コード生成
- コードレビュー・最適化
- バグ修正の提案
- 技術仕様書からのコードドラフト作成
コスト:ROIを最大化する選択を
%20.png?w=1200&h=500)
LLMの利用コストは、引き続き入力(プロンプト)と出力(生成されたテキスト)のトークン数(おおむね文字数や単語数に比例)に応じて課金されるのが一般的です。2025年上半期では、高性能モデルの価格がやや低下する傾向や、より安価な特定タスク向けモデルの選択肢が増える傾向が見られます。
以下、代表的なモデルの価格帯をご紹介します(2025年6月現在、各社公式発表に基づく参考価格。契約条件により変動する可能性があります)。
主要モデルの価格比較(100万トークンあたり)
モデル | 入力 (USD) | 出力 (USD) | 備考 |
|---|---|---|---|
OpenAI | |||
o3 | $10.00 | $40.00 | 高度な推論能力 |
GPT-4o | $2.50 | $10.00 | バランス型、マルチモーダル対応 |
o4-mini | $1.10 | $4.40 | 効率的な推論 |
GPT-4.1 | $2.00 | $8.00 | GPT-4oより安価、高性能 |
GPT-4.1-mini | $0.40 | $1.60 | コスト効率と性能のバランス |
Gemini 2.5 Pro (>200k tokens) | $2.50 | $15.00 | 大規模コンテキスト、高性能 |
Gemini 2.5 Pro (≦200k tokens) | $1.25 | $10.00 | |
Gemini 2.5 Flash (no thinking) | $0.15 | $0.60 | 高速・低コスト、前回記事の無料版から変更 |
Anthropic | |||
Claude Opus 4 | $15.00 | $75.00 | 最高性能、高度な推論 |
Claude Sonnet 4 | $3.00 | $15.00 | 高性能、思考プロセスあり |
Claude 3.5 Sonnet | $3.00 | $15.00 | 高品質、中程度の価格帯 |
xAI | |||
Grok 3 | $3.00 | $15.00 | 高性能、リアルタイムWebアクセス |
Grok 3 mini (with Thinking) | $0.30 | $0.50 | 低コスト、リアルタイムWebアクセス |
DeepSeek | |||
DeepSeek-R1-0528 (cache miss) | $0.55 | $2.19 | 高性能、特にコーディングと数学に強み |
以前は「無料」で高性能を謳っていたモデルも、API経由での本格的なビジネス利用では有料となるケースが一般的です。コスト評価においては、処理する総トークン量だけでなく、タスクの重要度や求める品質とのバランス、そしてモデルの「思考時間」や特殊機能の利用に伴う追加コストも考慮に入れる必要があります。
スピード:業務効率に直結する応答性能
LLMの処理速度は、主に2つの指標で評価されます。
レイテンシー(応答時間)
%20.png?w=1200&h=498)
入力から最初の出力が得られるまでの時間を示します。リアルタイムの対話が必要な用途では特に重要です。
この値が低い方が「出力までのスピードが早い」ということになります。
レイテンシーが重要になる活用例
- カスタマーサポートチャット
- 社内問い合わせ対応
- リアルタイムの翻訳支援
- インタラクティブなコーディング支援
アウトプット(処理能力)
%20.png)
一定時間内に処理できる処理数を示します。大量のデータ処理が必要な場合に重要です。
この値が高い方が「短い時間で多くの情報を回答できる」ということになります。
スループットが重要になる活用例
- 大量文書の一括要約・分類
- バッチ処理での文書生成
- 大規模データの分析・レポート作成
主要サービスの特徴と選び方
2025年上半期も各社から特徴的なLLMが提供されています。ここでは主要なプロバイダーとそのモデルシリーズの概要、おすすめの用途を解説します。
OpenAI:GPTシリーズ、oシリーズ
依然として業界をリードするOpenAIは、汎用性の高い「GPTシリーズ」と、より高度な推論能力に特化した「oシリーズ」の二本柱で展開しています。
おすすめの用途
- 複雑な分析レポートの作成 (o3, GPT-4.1)
- 高度な技術文書の執筆支援 (GPT-4.1)
- 最先端のプログラミング支援 (GPT-4.1)
- 一般的なビジネス利用、マルチモーダルタスク (GPT-4o)
- コストを抑えた定型業務の自動化 (GPT-4.1-mini, GPT-4.1-nano, o4-mini)
主要モデルの特徴
- o3: o1-previewに次ぐ高度な推論能力を持ち、ややコストを抑えたモデル。
- GPT-4o: 高いマルチモーダル性能とバランスの取れた価格設定。リアルタイム対話や多様な入力形式を扱う業務に適しています。
- o4-mini: 特定の推論タスクにおいて高いコストパフォーマンスを発揮します。
- GPT-4.1: GPT-4oと比較して、より長いコンテキスト処理や複雑な指示への追従性、コーディング能力が向上し、コストも抑えられています。汎用的な高性能モデルとして注目されます。
- GPT-4.1-mini / GPT-4.1-nano: GPT-4.1のアーキテクチャを継承しつつ、さらにコストと速度を最適化したモデル。大量処理やシンプルなタスクの自動化に適しています。
Google:Geminiシリーズ
GoogleのGeminiシリーズは、強力なマルチモーダル機能と、最大100万トークンという広大なコンテキストウィンドウ(Gemini 2.5 Pro)が最大の特徴です。Googleの各種サービスやインフラとの連携も強みです。
おすすめの用途
- 超長文の文書(書籍、研究論文、契約書など)の読解・分析・要約 (Gemini 2.5 Pro)
- 画像、音声、動画を含むドキュメントの統合的処理 (Gemini 2.5 Pro, Gemini 2.5 Flash)
- Google Cloudとの連携を前提とした企業システムへのAI組み込み
主要モデルの特徴
- Gemini 2.5 Pro: 最大100万トークンという圧倒的なコンテキスト長を誇り、非常に大量の情報を一度に処理できます。マルチモーダル性能も高く、複雑なデータ分析や企業ナレッジの活用に適しています。
- Gemini 2.5 Flash: 非常に高速かつ低コストでありながら高い性能を維持しており、リアルタイム応答が求められるチャットボットや、大量のリクエストを処理するタスクに適しています。
Anthropic:Claudeシリーズ
AnthropicのClaudeシリーズは、長文の理解・生成能力の高さと、より自然で倫理的な対話性能を重視して開発されています。Claude 4系の「Thinking」モードでは、応答生成前に内部的な「思考プロセス」を経ることで、より複雑な指示への対応や推論の精度向上を図っています。
おすすめの用途
- 高品質な長文ドキュメント(レポート、記事、クリエイティブライティング)の作成・編集 (Claude Opus 4, Claude Sonnet 4)
- 詳細な市場調査レポート作成、法務・学術文書の分析 (Claude Opus 4)
- 複雑な指示に基づいたタスク実行、エージェント的な振る舞い (Claude Opus/Sonnet 4 "Thinking" モード)
- リアルタイム応答が求められるチャットボット、カスタマーサポート (Claude 3.5 Haiku)
主要モデルの特徴
- Claude Opus 4: Anthropicのフラッグシップモデル。最高の性能と最も高度な推論能力を提供しますが、コストも最も高価です。
- Claude Sonnet 4: Opus に匹敵する高い文章理解力と生成能力を持ちつつ、コストを抑えたモデル。多くのビジネス用途で高いパフォーマンスを発揮します。
- Claude 3.5 Sonnet: 依然として高い性能を持つバランスの取れたモデル。レポート作成や編集業務に適しています。
- Claude 3.5 Haiku: 非常に高速な処理が可能で、コストも低く抑えられています。チャットボットなどのリアルタイム応答や、大量のタスク処理に向いています。
xAI:Grokシリーズ
xAIのGrokシリーズは、リアルタイムのWeb情報へのアクセス能力と、ユーモラスで時に挑発的な応答スタイルが特徴です。X(旧Twitter)との連携も強みとなる可能性があります。
おすすめの用途
- 最新情報に基づいた調査・分析
- アイデア生成、ブレインストーミング
- エンゲージメントを重視するコンテンツ作成
主要モデルの特徴
- Grok 3: 高いMMLUスコアを誇り、最新情報へのアクセス能力と組み合わせることで、時事性の高いトピックに関する深い洞察を提供します。
- Grok 3 mini (with Thinking): Grok 3の能力をより低コストで利用可能にしたモデル。高速な応答も特徴です。
DeepSeek:DeepSeek R1シリーズ
DeepSeek AIによって開発されたDeepSeek R1シリーズは、特にコーディングと数学の分野で非常に高い性能を示すオープンソース(一部商用利用制限あり)のモデルとして注目されています。
おすすめの用途
- 高度なプログラミング支援、コード生成・バグ修正
- 数学的問題解決、データサイエンス分野での活用
- 研究開発、学術用途
主要モデルの特徴
- DeepSeek-R1: 特に数学・コーディングの難関ベンチマークでトップクラスの性能を示しており、専門性の高いタスクでの活用が期待されます。オープンソースでありながら商用レベルの性能を持つ点が大きな特徴です。
LLM選定の基本フロー
LLMの選定は、以下のステップで進めるのが効果的です。
Step 1:用途の明確化
- LLMに何をさせたいのか?(文章生成、要約、翻訳、質疑応答、コード生成、画像認識、感情分析など)具体的なタスクを列挙します。
- 想定される使用頻度(例:1日数回、常時大量アクセス)や処理量(例:短いテキスト、長文レポート)を見積もります。
- セキュリティ要件(データの取り扱い、オンプレミス/クラウドなど)を確認します。特に機密情報を扱う場合は、提供元のセキュリティポリシーやデータ保持期間などを詳細に確認する必要があります。
Step 2:必要な性能レベルの特定
- 求められる精度: タスクによって許容される誤りの範囲は異なります。「完璧に近い」品質が必要か、ある程度の誤りがあっても後工程で修正可能かなどを定義します。
- 許容される応答時間: リアルタイム性が求められるか、バッチ処理で問題ないか。ユーザー体験に直結する部分です。
- 必要なコンテキスト長: 一度に処理する必要がある情報の量。長文の契約書分析と、短いFAQ応答では大きく異なります。
- 推論能力の要否: 単純な情報検索や定型的な文章生成か、複雑な指示理解や論理的な思考、専門知識の活用が必要か。
Step 3:コストの検討
- 月間あるいはプロジェクト期間中の予想使用量(入力トークン数、出力トークン数)を算出します。
- 各モデルの料金体系に基づき、総コストを見積もります。特定の機能(高解像度画像処理、長時間思考モードなど)に追加コストがかかる場合もあるため注意が必要です。
- 予算との整合性を確認し、投資対効果(ROI)を試算します。初期開発コスト、運用コスト、そしてLLM導入によって得られる効率化や付加価値を総合的に評価します。
Step 4:試験運用と評価
- PoC (Proof of Concept) の実施: まずは小規模な検証環境で、いくつかの候補モデルを実際に試用します。
- 実際の業務データでのテスト: 机上のベンチマークスコアだけでなく、自社の実際の業務データやユースケースでテストし、実用的な品質や性能を評価します。
- ユーザーフィードバックの収集: 実際にLLMを利用する(あるいはその結果を見る)ユーザーからのフィードバックを収集し、改善点や満足度を把握します。
- 複数モデルの比較検討: 特定のモデルに固執せず、複数のモデルを比較検討し、それぞれの長所・短所を理解することが重要です。
まとめ:2025年のLLM活用に向けて
2025年上半期もLLM技術は目覚ましい進化を遂げ、各社から多様な選択肢が提供されています。特に、OpenAIの「o3」「o4-mini」やGPT-4.1シリーズ、Googleの「Gemini 2.5 Pro/Flash」、Anthropicの「Claude 4」、そして新たに注目されるxAIの「Grok」やDeepSeekの「DeepSeek R1」など、高性能化と専門特化が進んでいます。
しかし、常に最新・最高性能のモデルが自社にとって最適解とは限りません。技術の進化は著しいものの、それに伴い利用コストも考慮すべき重要な要素です。例えば、高度な推論や専門知識が求められる業務には上位モデル(例:OpenAI o3, Anthropic Claude Opus 4)を、定型的な文章作成やリアルタイム応答が重要なチャットボットにはコスト効率の良い高速モデル(例:OpenAI GPT-4.1-mini, Google Gemini 2.5 Flash, Anthropic Claude 3.5 Haiku)を選択するなど、タスクに応じたモデルの使い分けが一層効果的になっています。
さらに、複数のモデルを組み合わせて利用することで、コストと性能のバランスを最適化するアプローチも現実的な選択肢です。例えば、日常的な問い合わせ応答には低コストなモデルを使用し、複雑で重要度の高い分析業務にのみ高性能モデルを限定的に利用するといったハイブリッドな活用方法が考えられます。
Biz Freakでは、このようなAIツールの効果的な活用方法を学び、実践できる環境を提供しています。独自のAIシステムとローコードを組み合わせることで、短期間で高品質なプロダクトを実装する能力を養うことができます。 https://bizfreak.co.jp/recruit
参考文献
- Artificial Analysis「Independent analysis of AI models and API providers」 https://artificialanalysis.ai/
(M.H)


